
Evaluators for the Agentic Era
End-to-End LLM based evaluators for Multi-agent Workflows

This post covers what trajectory-aware, tool-using evaluation is, how the research landscape has evolved, and how to build a complete agentic evaluator you can run today. Code is at github.com/RGaonkar/AgenticEvals.
There are two versions of the LLM evaluation problem.
The first version is a lot easier to compute. Does the model produce factually correct, well-formed answers on a held-out test set? ROUGE, BERTScore, exact match, LLM-as-a-judge. These are all answers to that question, and for single-turn systems, they work well enough.
The second version is harder and mostly unsolved in practice: does this agent reason well through a multi-step task? Not just did it get the answer right, but did it get there in a way that will generalize, that you can audit, that won’t catastrophically fail when your task distribution shifts?
These require fundamentally different evaluation designs. If you are building products where models use tools, call APIs, or execute multi-turn task plans, your existing evaluator is measuring the wrong thing. This post explains what to measure instead, how the research community has structured the problem, and gives you a working implementation to fork and extend.
Why answer-only evaluation breaks for agents
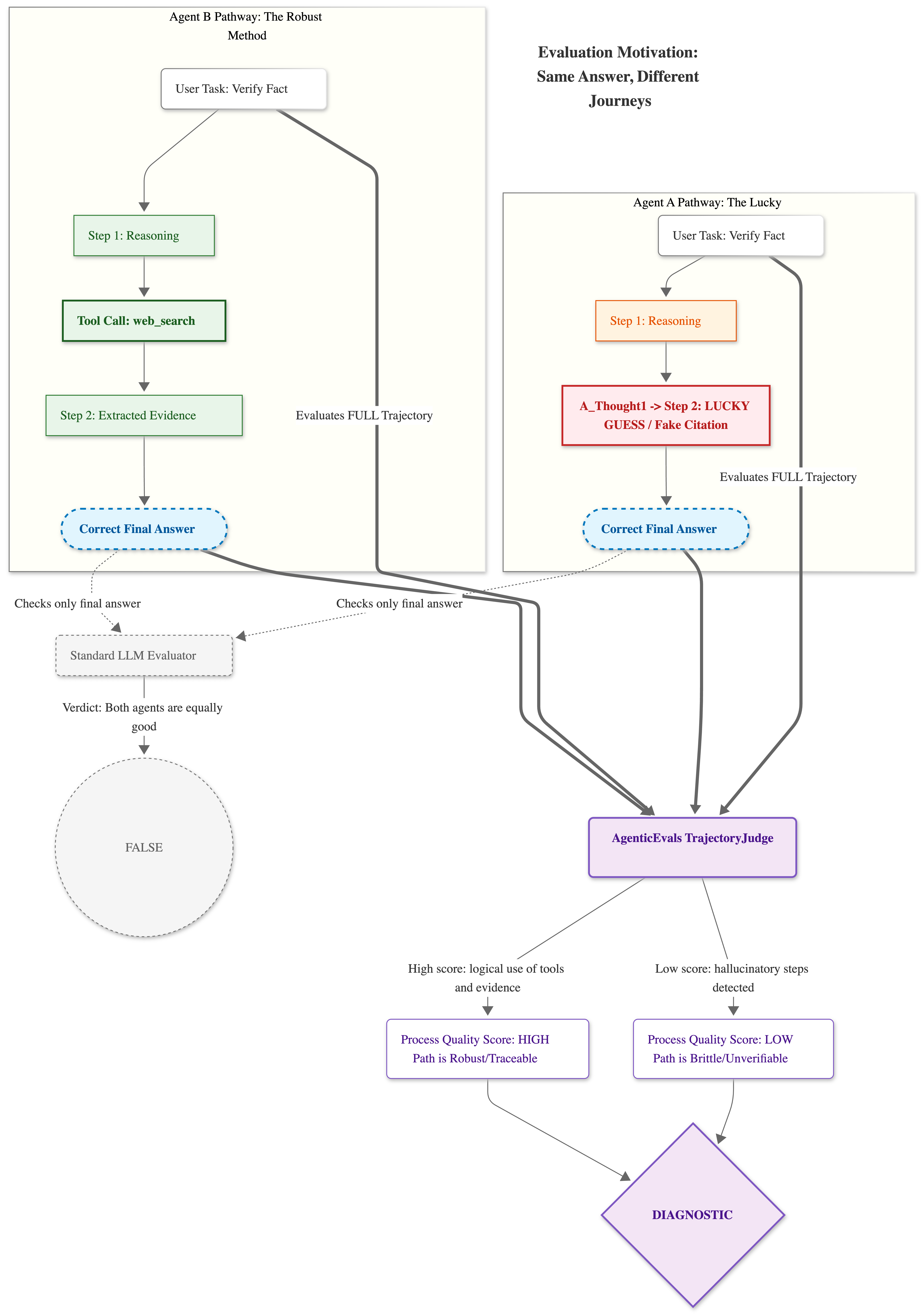
The failure mode has a clean illustration:
Two agents answer the same factual question requiring a recent web search.
Agent A issues a plausible-sounding internal synthesis, cites two sources it fabricated, and returns the correct answer.
Agent B issues three targeted search queries, reads the two most relevant pages, extracts supporting evidence explicitly, and arrives at the same answer through verifiable reasoning.
A standard evaluator gives them identical scores. In production, Agent A fails the moment your query distribution shifts. Agent B is a system you can reason about and improve.
The implication for post-training is more serious. If you are using evaluation scores as a reward signal (for RLHF, DPO, or any form of RL-based agent training), an answer-only evaluator is a proxy gaming setup by construction. The model will learn to get the right answer by whatever means available, including means you explicitly don’t want. This is the reward hacking problem applied to evaluation itself.
The fix is to evaluate trajectories, not answers. You can see the diagram below to get a better intuition of this problem.
The research landscape
Three lines of progress have converged on this problem. Understanding the taxonomy helps you make the right design choices.
Preference-style LLM judges
MT-Bench and related work established that a strong judge model (GPT-4, Claude) can achieve human-level agreement (roughly >80% match rate in their setup) when evaluating open-ended responses via pairwise comparison or rubric scoring. This delivers scale and coverage that human annotation cannot match.
The limitation is that these judges evaluate only the final outputs. They also exhibit well-documented biases: position bias (preferring the first response), verbosity bias (preferring longer answers), and self-enhancement (preferring outputs that resemble the judge’s own style). G-Eval addressed some of these through chain-of-thought decomposition before scoring, and JudgeLM addressed them at training time through swap augmentation and mixed-format training.
But none of these systems evaluate the process. They see what the agent said, not what it did to get there.
Search-augmented factuality evaluators
FActScore (Min et al., EMNLP 2023) and SAFE (Wei et al., 2024) represent a different approach: decompose the agent’s output into atomic claims, then verify each claim against external evidence via retrieval or web search. SAFE reports 72% agreement with crowd annotations at substantially lower cost than human evaluation, and applies this to long-form outputs where holistic scoring is unreliable.
This is already more agentic than preference-style judging, the evaluator itself uses tools. But the tool-use policy is trivial: verify every claim, always. There is no decision about when to search, which makes these systems expensive at scale.
Iterative, decision-making verification agents
FIRE (Xie et al., NAACL Findings 2025) is the closest thing to a fully agentic evaluator: an iterative loop where the judge decides at each step whether to issue another search query or finalize its verdict based on current confidence. The reported cost reductions are significant: roughly 7.6× lower LLM cost and 16.5× lower search cost relative to fixed-N retrieval baselines, with equivalent or slightly better verification accuracy.
The FIRE architecture maps directly onto how a human expert would verify a complex claim: form an initial judgment, identify what you don’t know, search for it, update, and stop when confident enough.
Adaptive-RAG provides a complementary idea for the routing decision: train a lightweight classifier that routes each evaluation request to one of several modes between no search, single-query search, or iterative multi-hop search, based on predicted query complexity. This separates “do I need to search at all” from “how much searching do I need.”
These three families are not mutually exclusive. The strongest evaluator architecture synthesizes all three: preference-style rubric scoring for process quality, claim decomposition for factuality verification, and adaptive tool-use decisions for cost efficiency.
What trajectory-aware evaluation measures
A trajectory is the complete interaction record of an agent on a task:
[USER] What was the closing price of TSLA on Feb 14, 2025?
[ASSISTANT] I'll search for this.
tool_calls: [web_search({"query": "TSLA closing price February 14 2025"})]
[TOOL] [web_search] Top results: 1. MarketWatch — TSLA closed at $355.84...
[ASSISTANT] The closing price of Tesla (TSLA) on February 14, 2025 was $355.84.
An evaluator operating on this trajectory can assess:
Correctness: Does the final answer match the reference?
Process quality: Did the agent take logical, purposeful steps?
Tool use: Were tools invoked with appropriate arguments at the right time?
Reasoning coherence: Is the chain of thought consistent and traceable?
Evidence grounding: Does the final answer derive from the retrieved evidence?
The output is multi-dimensional; no single score tells the full story:

The gap between trajectory_score and exact_match is diagnostic. Large gap with high trajectory score: the agent is reasoning well, but not matching the reference format. This is a post-processing or prompt problem, not a capability problem. High exact match with low trajectory score: Agent A, you got lucky, and you should be worried about it.
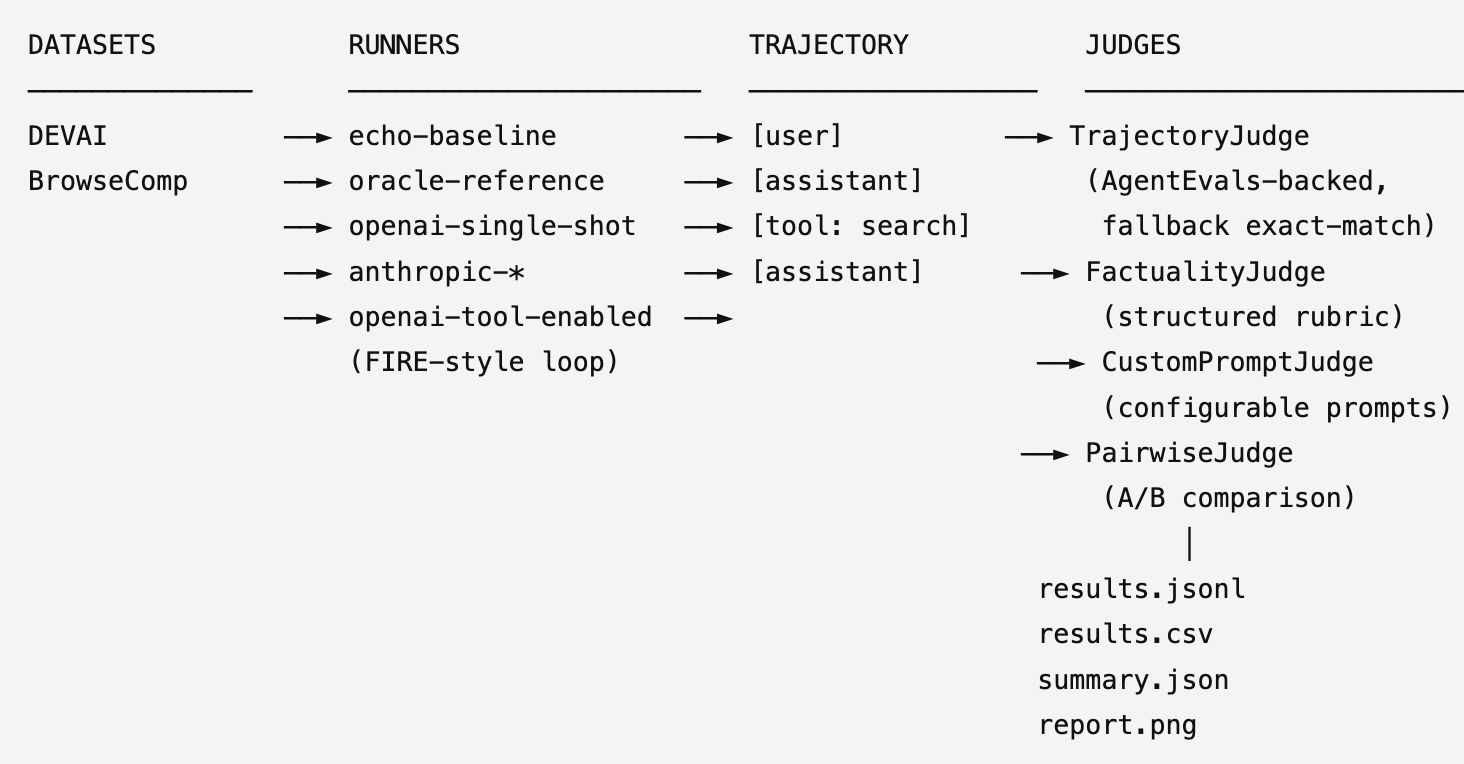
Architecture of the evaluator
The evaluation stack has four components. Here is how they map to the codebase:
The data model
Everything flows through three Pydantic types. TraceStep is the atomic unit:
class ToolCall(BaseModel):
function: str
args: dict[str, Any] = Field(default_factory=dict)
class TraceStep(BaseModel):
role: Literal["user", "assistant", "tool", "system"]
content: str | None = None
tool_calls: list[ToolCall] = Field(default_factory=list)All runners produce list[TraceStep], all judges consume it. This typed interface makes it straightforward to swap agent implementations without touching the evaluation logic, and to swap judge implementations without touching the runner.
Runners
The runner interface is minimal:
class BaseRunner(ABC):
name: str
@abstractmethod
def run(self, task: TaskRecord) -> list[TraceStep]:
...Five implementations are included in the repo:
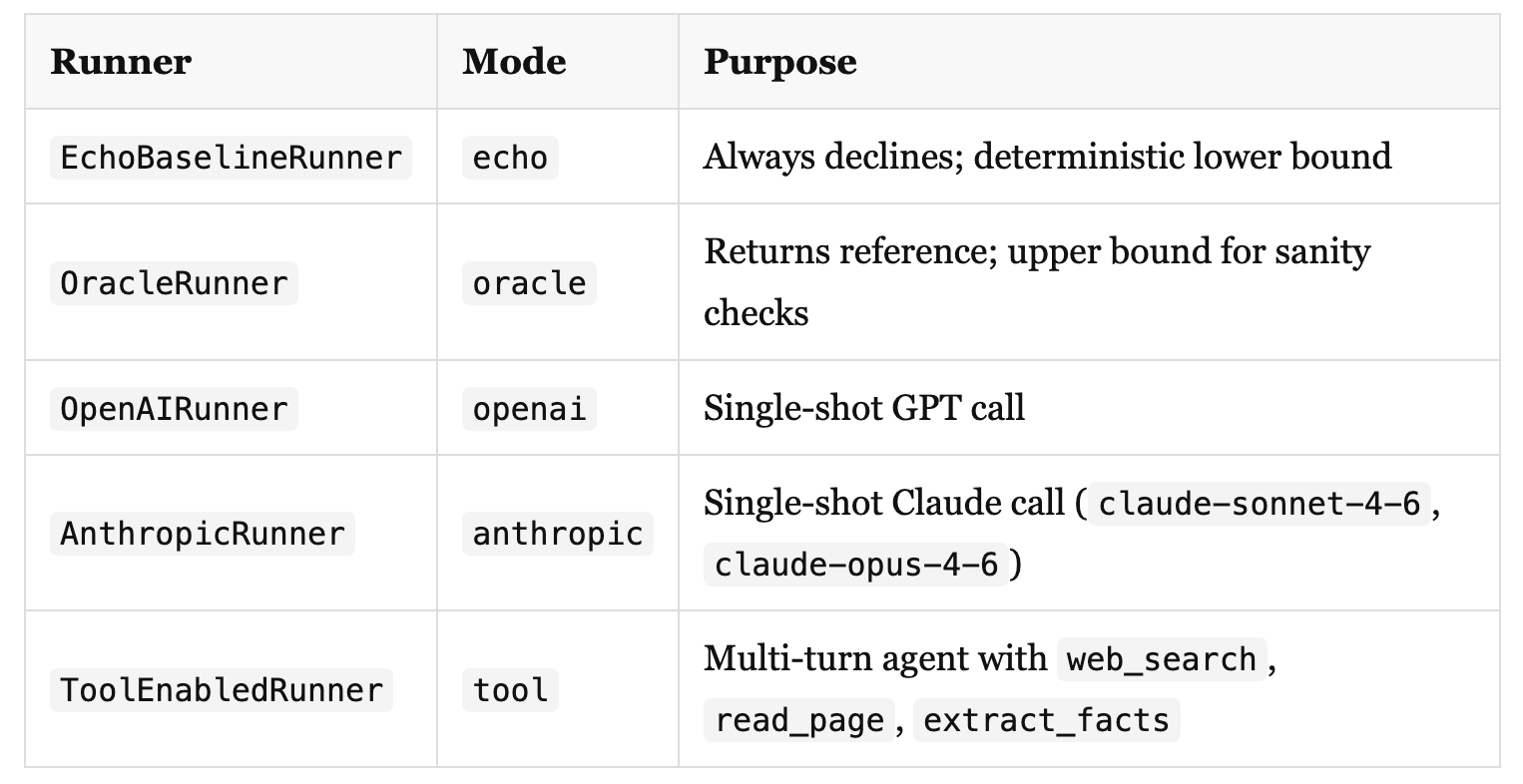
Running the echo and oracle baselines first is not optional. Before trusting any score from a real agent, you need to confirm that your judges are not trivially giving high scores (echo should be near zero) and that they respond correctly to a perfect answer (oracle should be near one). Any deviation from this means your judge is miscalibrated before you even start.
The tool-enabled runner: a FIRE-style loop
The most interesting component for evaluating agentic behavior is the tool-enabled runner. The design directly follows FIRE’s “verify-or-continue” pattern.
After each round of tool use, the agent calls a report_confidence function with a score from 0.0 to 1.0 and a brief rationale. If confidence exceeds a configurable threshold (default 0.8), the loop stops and the agent synthesizes a final answer. If not, it continues gathering evidence up to max_turns.
class ToolEnabledRunner(BaseRunner):
def __init__(
self,
model: str = "gpt-4o-mini",
max_turns: int = 6,
confidence_threshold: float = 0.8,
) -> None:
...The three primary tools:
_TOOLS_SCHEMA = [
{
"function": {
"name": "web_search",
"description": "Search the web for current information about a topic.",
...
}
},
{
"function": {
"name": "read_page",
"description": "Fetch and read the content of a web page by URL.",
...
}
},
{
"function": {
"name": "extract_facts",
"description": "Extract key facts from a body of text relevant to a question.",
...
}
},
]The default implementation uses stub tool results, which are descriptive enough for the LLM to reason about them and produce coherent trajectories, but not backed by real APIs. Plugging in real tool implementations is a one-function change:
def _stub_tool_result(name: str, args: dict) -> str:
if name == "web_search":
return f"[web_search stub] Top results for '{args['query']}': ..."
...Replace this function with calls to Brave Search, Serper, Tavily, or a headless browser. The trajectory capture, judge, and pipeline code stay unchanged.
The confidence-based stopping serves two purposes. First, it produces more informative trajectories: an agent that stops early because it found the answer in one query generates a different and meaningful signal compared to one that exhausts all turns. Second, it directly mirrors the FIRE finding. Most claims can be resolved with fewer searches than a fixed budget allocates, and forcing the agent to report confidence creates an explicit stopping condition that the evaluator can score.
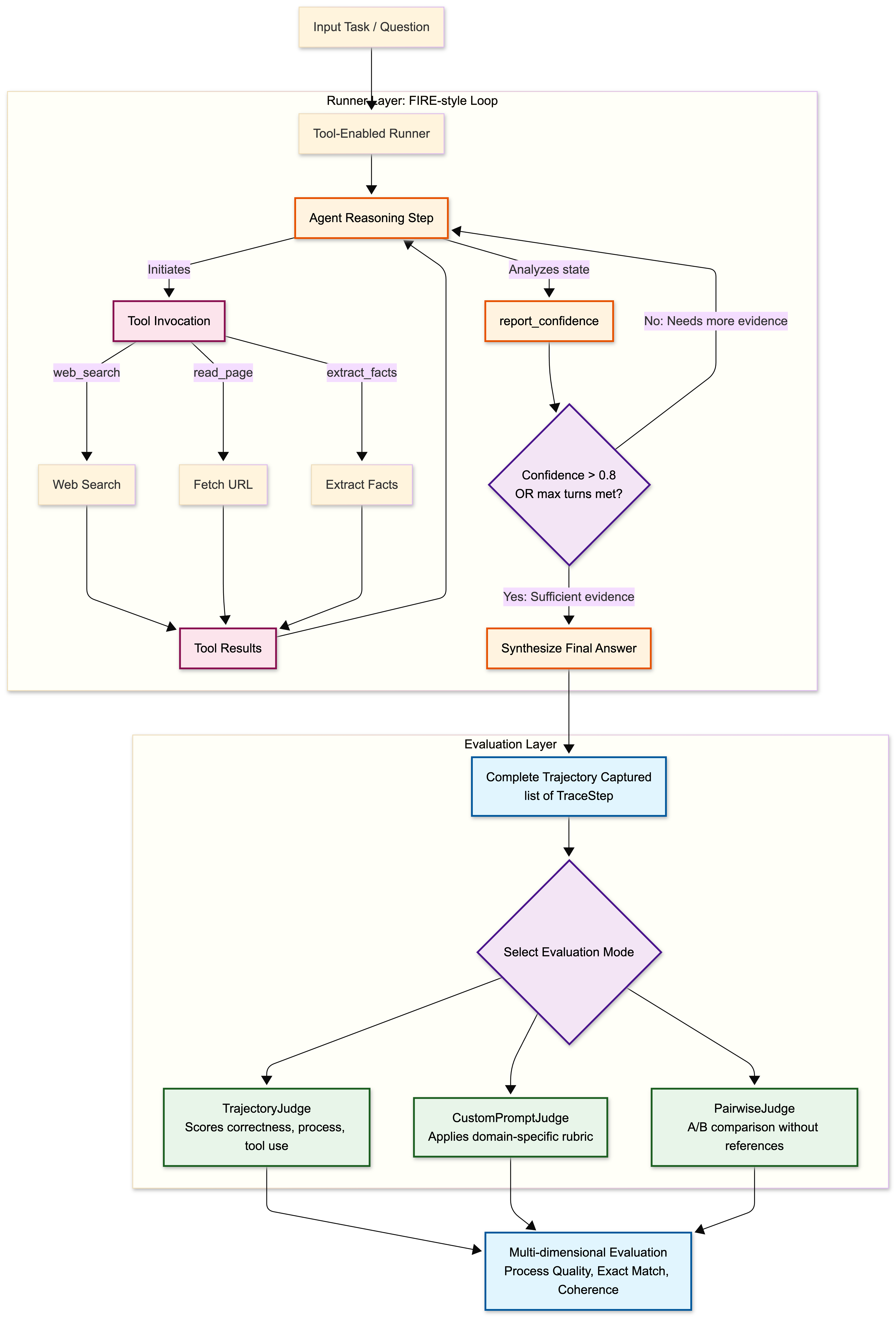
The judges
TrajectoryJudge
The primary judge wraps AgentEvals’ create_trajectory_llm_as_judge. If that library is unavailable or the call fails, it falls back to exact-match. The graceful degradation is intentional because it keeps the repo runnable across environments while still supporting the intended trajectory-judge path.
The formatted trajectory that the judge receives looks like this:
[USER] What was the closing price of TSLA on Feb 14, 2025?
[ASSISTANT] tool_calls: web_search({"query": "TSLA closing price February 14 2025"})
[TOOL] [web_search stub] Top results for 'TSLA closing price February 14 2025': ...
[ASSISTANT] The closing price was $355.84.FactualityJudge
Uses a structured scoring rubric rather than a binary correct/incorrect verdict:
1.00 - fully correct and consistent with the reference
0.75 — mostly correct; minor omissions or imprecision
0.50 — partially correct; captures the main idea but misses key details
0.25 — mostly incorrect but tangentially related
0.00 — completely wrong, irrelevant, or no answer provided
Structured rubrics matter here. Prometheus showed that rubric conditioning is the primary driver of evaluator–human agreement (Pearson 0.897 in their setup). A coarse binary verdict misses the partial-credit signal that is most useful for iterating on agents.
The judge returns a structured JSON:
{"score": 0.75, "comment": "...", "verdict": "partial"}Requiring structured outputs from the judge is a robustness measure. JudgeDeceiver demonstrated that free-form judge outputs are more susceptible to prompt injection, both from the evaluated answer and from retrieved web content. Narrowing the output space reduces the attack surface.
CustomPromptJudge
Domain-generic judge criteria drift quickly. A coding agent should be judged on whether it correctly interprets requirements before writing code. A document processing agent should be judged on whether it reads the right sections and flags uncertainty appropriately. A search agent should be judged on query specificity and source synthesis.
The CustomPromptJudge separates prompt templates from judge logic:
from agentic_evals.judges.trajectory import CustomPromptJudge
from agentic_evals.judges.prompts import TRAJECTORY_ACCURACY_SYSTEM
judge = CustomPromptJudge(
model="gpt-4o",
system_prompt=TRAJECTORY_ACCURACY_SYSTEM, # or your domain-specific rubric
user_prompt=MY_CUSTOM_TEMPLATE, # format vars: {reference}, {trajectory}
)
result = judge.evaluate(trajectory=steps, reference="...")
All prompt templates live in judges/prompts.py and use Python format strings. Override the system prompt to inject domain-specific criteria without touching the judge logic.
PairwiseJudge
When iterating on agent configurations, you often want relative quality measurements rather than absolute scores. The PairwiseJudge is designed for this:
from agentic_evals.judges.trajectory import PairwiseJudge
judge = PairwiseJudge(model="gpt-4o-mini")
result = judge.compare(trajectory_a=steps_v1, trajectory_b=steps_v2)
# {"winner": "B", "score_a": 0.62, "score_b": 0.84, "comment": "..."}
No reference answer required. This maps cleanly onto the ARES insight about data-efficient evaluation: for agent A/B experiments during development, pairwise comparison with a small set of tasks gives you a faster signal than running a full rubric-scored evaluation on every iteration.
Calibration and reliability: the things most teams skip
Getting evaluation scores is straightforward. Trusting them is harder.
Run your baselines first. Echo and oracle are not demonstration code, they are calibration tools. If your judge gives a non-trivial score to an agent that always refuses to answer, your judge is broken. ARES formalizes this as prediction-powered inference: use a small human-labeled set to correct for systematic judge errors before using the scores as rewards or filters.
Test for epistemic marker bias. EMBER showed that LLM judges can penalize uncertainty expressions and flip verdicts when an agent says “I’m not certain but...” versus “The answer is...”. For a search agent that is supposed to express calibrated uncertainty, this is a serious failure mode. Run a perturbation ablation: take your evaluated outputs, add or remove uncertainty language, and measure verdict stability. If the judge flips significantly, you need to harden your judge prompt.
Treat the judge prompt as a security surface. If your tool-enabled runner retrieves real web content, that content can contain prompt-injection attacks. JudgeDeceiver demonstrated high success rates for manipulating LLM judges through strategically crafted content in the evaluated answer. Retrieved web content is an additional attack vector. The mitigations are practical: quote retrieved text rather than injecting it raw into the prompt, keep the system prompt immutable, and strip instruction-like patterns from web content before it enters the judge context.
Separate the tool-use decision signal from the answer style. If your confidence-based stopping uses the agent’s reported confidence as a proxy for actual answer quality, you are vulnerable to the same epistemic marker bias. FIRE’s implementation grounds confidence in retrieved evidence rather than the model’s self-assessment. In production, pair the confidence signal with an independent verification step. At minimum, check whether the retrieved evidence actually contains the claimed facts.
Running it
git clone https://github.com/RGaonkar/AgenticEvals.git
cd agenticEvals
python -m venv .venv && source .venv/bin/activate
pip install -e .
cp .env.example .env # add OPENAI_API_KEY, ANTHROPIC_API_KEY, HF_TOKEN
Run the calibration baseline first:
# Lower bound — confirm judges aren't inflated
agentic-evals run --dataset devai --limit 20 --agent-mode echo
# Upper bound — confirm judges respond correctly to perfect answers
agentic-evals run --dataset devai --limit 20 --agent-mode oracle
Then run the real agents:
# Single-shot GPT
agentic-evals run --dataset devai --limit 20 --agent-mode openai --agent-model gpt-4o
# Single-shot Claude
agentic-evals run --dataset devai --limit 20 --agent-mode anthropic --agent-model claude-sonnet-4-6
# Tool-enabled with FIRE-style confidence stopping
agentic-evals run \
--dataset devai \
--limit 20 \
--agent-mode tool \
--agent-model gpt-4o \
--judge-type custom
# BrowseComp (auto-redacts all benchmark text in output)
agentic-evals run \
--dataset browsecomp \
--limit 20 \
--agent-mode toolLoad from a YAML config for reproducible experiments:
agentic-evals run --config configs/experiment.browsecomp.yamlGenerate visualization and print aggregate metrics:
agentic-evals report runs/<run_dir>
agentic-evals summary runs/<run_dir>What the numbers should tell you
A correctly calibrated evaluation run on a real agent looks roughly like this:
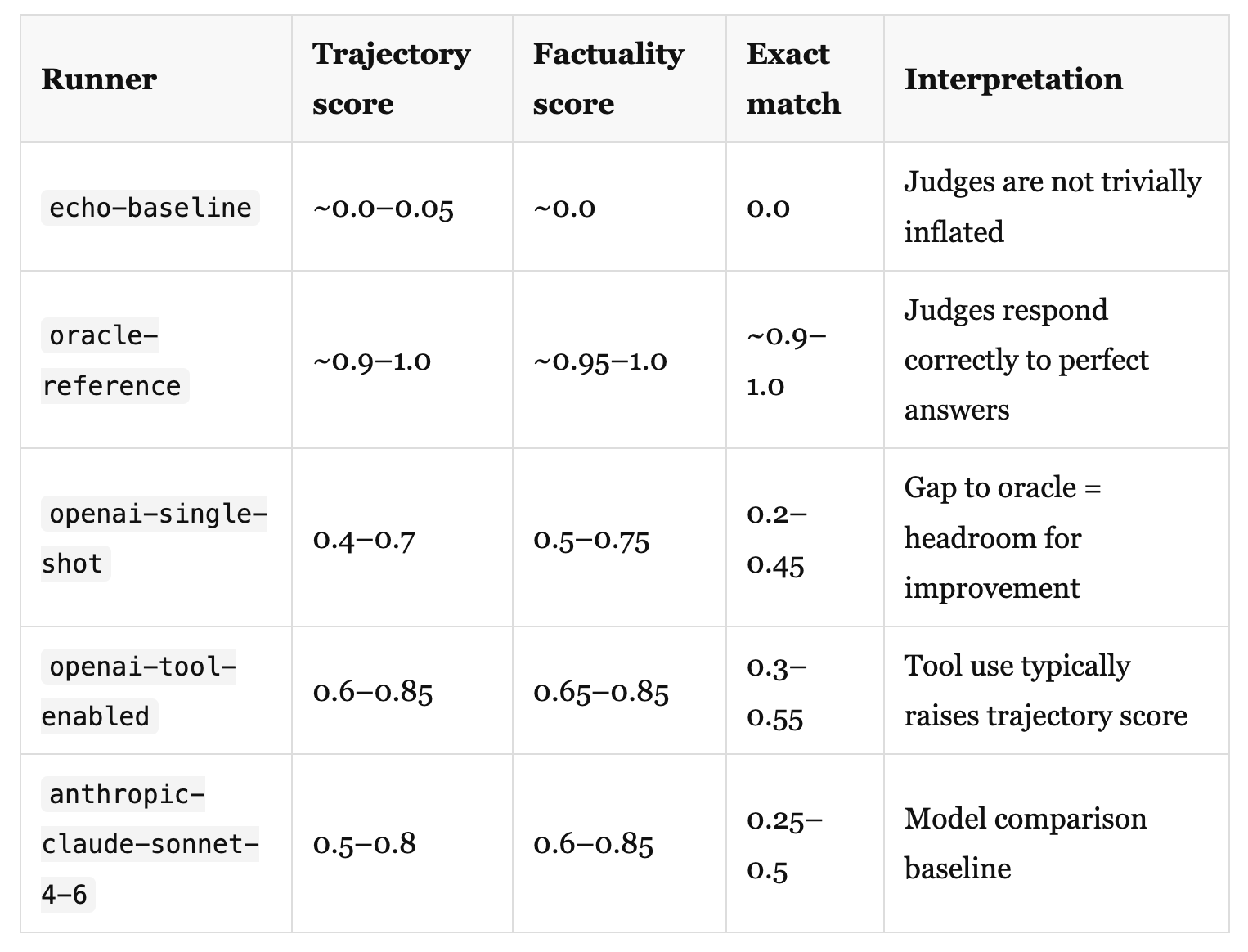
These are representative ranges, not guarantees. The actual numbers depend heavily on the benchmark and judge model.
The comparison that matters most is tool-enabled vs single-shot on trajectory score. If the tool-enabled runner is not scoring higher on trajectory quality than single-shot despite making the right tool calls, then your trajectory judge criteria are not capturing process quality. Revisit your judge prompt!
What to build next
Real tool implementations. Replace _stub_tool_result with a live search API. Brave Search, Serper, and Tavily all have free tiers. The trajectory capture and judge code are unchanged.
SAFE-style claim decomposition. For factuality evaluation on long-form outputs, add a claim extraction step before the factuality judge: split the agent’s answer into atomic claims, verify each independently, and aggregate. This catches fluent hallucinations that holistic scoring misses.
Anthropic as judge. The CustomPromptJudge currently uses OpenAI for the judge model. Swapping in the Anthropic client and using claude-opus-4-6 as judge is a one-class change. For reasoning-heavy tasks, Claude’s extended thinking mode produces more calibrated judge scores.
ARES-style calibration. Collect a small human-labeled set (200–500 tasks with verified claim labels), then use prediction-powered inference to correct for systematic judge errors. This gives you confidence intervals on your evaluation scores, which matters significantly if you are using them as post-training rewards.
Adaptive routing. Train a lightweight classifier that routes each evaluation request to the appropriate mode: no search (judge internally), single search, or iterative multi-hop. Adaptive-RAG demonstrates that even a small router can capture most of the quality benefit of always-search at a fraction of the cost.
Post-training integration. trajectory_score and factuality_score are natural candidates for reward model training data. The structured output format maps directly to preference pairs: high-scoring trajectory vs low-scoring trajectory on the same task, with the judge comment as rationale.
The design principle that runs through all of this
The research consensus is that the core challenge for agentic evaluators is not the judge model’s capability, but the quality and structure of the evaluation signal. Frontier models are capable enough.
An evaluator that only checks final answers will train an agent to find the answer by any means. An evaluator that checks process quality will train an agent to reason well. An evaluator that uses tools adaptively will give you a more reliable signal at a lower cost than one that always searches or never searches.
The framework in this repo is a starting point for the latter. The stubs are intentional: they let you run the full evaluation loop, understand the signal structure, and then replace them with real implementations when you have them. The judge prompts are templates: they give you a working default that you should replace with domain-specific criteria before using scores as rewards.
The most important move is to run your baselines first, check calibration, and then trust your numbers. Without that, you are building on a foundation you haven’t verified!
Full implementation at github.com/RGaonkar/AgenticEvals. Fork it, run the baselines, replace the stubs with real tools, and adapt the judge criteria to your domain.
If you are building agentic evaluation into a post-training pipeline, especially in an enterprise setting where reliability of the reward signal matters, I’d like to hear what criteria you are using and what failure modes you’ve run into.
Next: calibrating the judge model itself, measuring judge accuracy, detecting systematic biases, and producing confidence intervals on evaluation scores using prediction-powered inference.